关于 GraphQL 这门技术,其实之前就有所关注,当时还是 React 刚发布的时候。那个时候,GraphQL 感觉还只是概念完备阶段,除了 FaceBook 自己内部大量使用外,好像社区并不是很健全,不过大家应该都在疯狂的讨论和跟进吧。这么几年过去,已经涌现出各种开源或商用服务专注于这个领域,各种语言的框架和工具也都很完备了,感觉是时候重新接触 GraphQL 了。如果你的项目正处于技术选型,你正在犹豫选择一种接口风格的时刻,不妨了解一下 GraphQL 这个神奇而强大的技术。
本文主要围绕 GraphQL 的 Server 端实现,因为相比 Client 端,Server 端包含了更多的内容。另外,关于 GraphQL 概念的内容,这篇文章并没有涉及太多,不过假如你用搜索引擎去搜的话,相信有非常多的相关文章供你学习,这里就不再重复了。
相信读完整个文章,对于 GraphQL Server 会有一个更加完整的了解。
目标
我们的目标是针对一个移动 app 端界面显示所需要的数据,提供支撑,可以实现单一请求次数下就可以获取足够的数据。我们将会用 Nodejs 来完成这个任务,因为这个语言我们已经用了 4 年了。但你也可以用任何你想用的语言,例如 Ruby,Go,甚至 PHP,JAVA 或 C#。
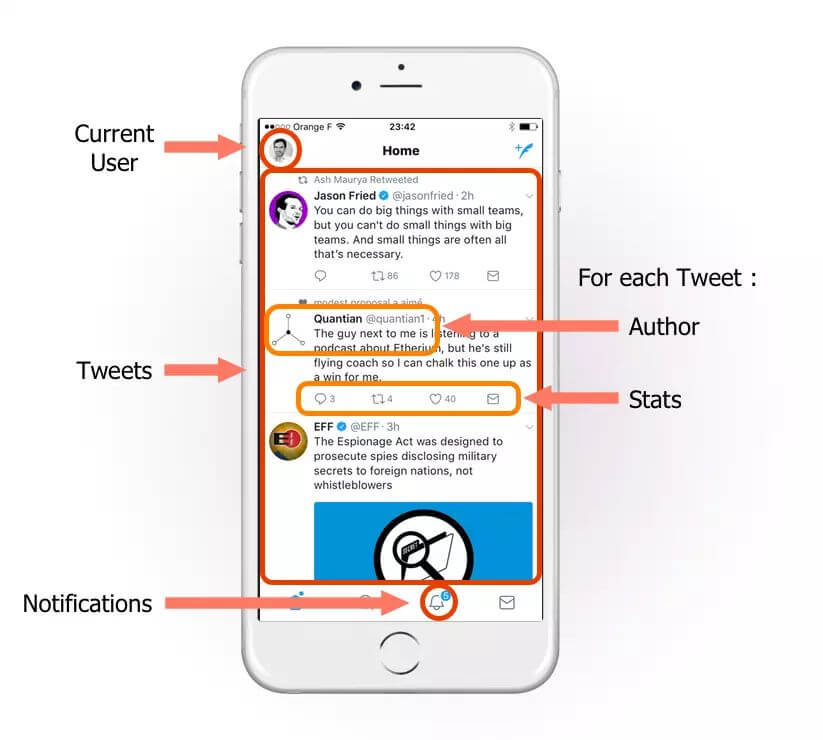
为了显示这个页面,服务端必须能提供下面的响应数据结构:
{
"data": {
"Tweets": [
{
"id": 752,
"body": "consectetur adipisicing elit",
"date": "2017-07-15T13:17:42.772Z",
"Author": {
"username": "alang",
"full_name": "Adrian Lang",
"avatar_url": "http://avatar.acme.com/02ac660cdda7a52556faf332e80de6d8"
}
},
{
"id": 123,
"body": "Lorem Ipsum dolor sit amet",
"date": "2017-07-14T12:44:17.449Z",
"Author": {
"username": "creilly17",
"full_name": "Carole Reilly",
"avatar_url": "http://avatar.acme.com/5be5ce9aba93c62ea7dcdc8abdd0b26b"
}
},
// etc.
],
"User": {
"full_name": "John Doe"
},
"NotificationsMeta": {
"count": 12
}
}
}我们需要模块化和可维护的代码,需要做单元测试,听起来这很难?你会发现借助于 GraphQL 工具链,这并不比开发 Rest 客户端难多少。
一切从 Schema 开始
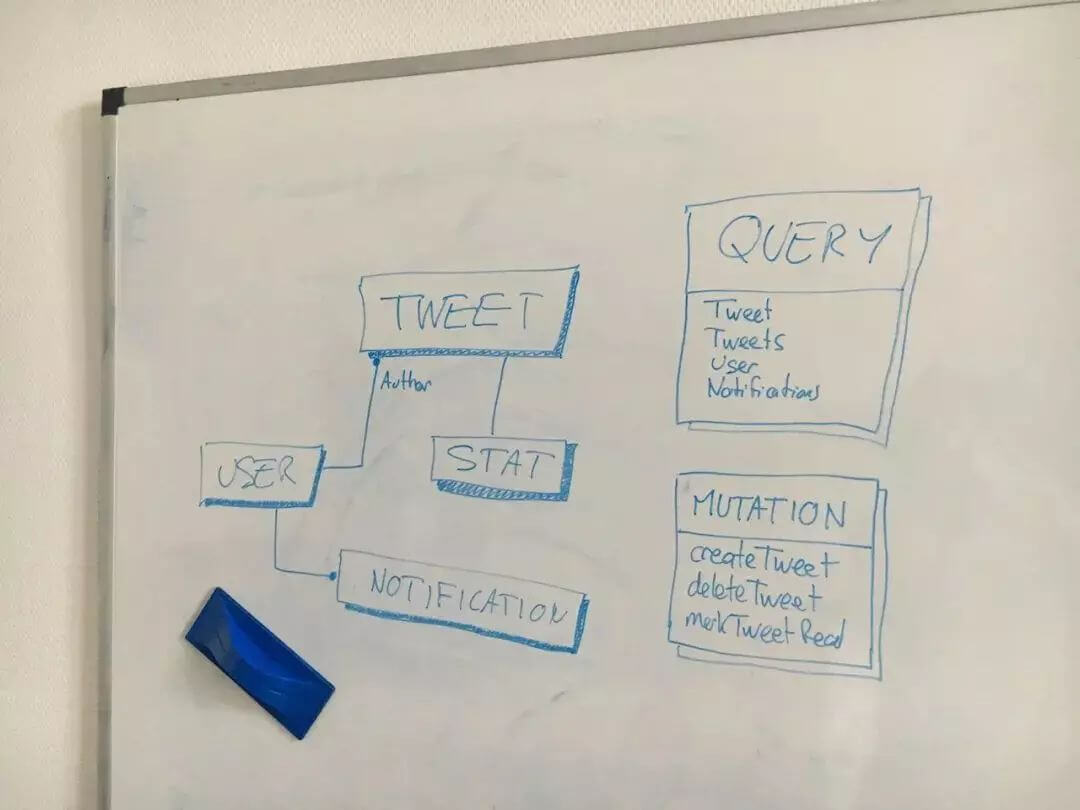
当我开发一个 GraphQL 服务时,我总会从在白板上设计模型开始,而不是上来就写代码。我会和产品和前端开发团队一起来讨论需要提供哪些数据类型,查询或更新操作。如果你了解领域驱动设计方法,你会很熟悉这个流程。前端开发团队在拿到服务端返回的数据结构之前是没有办法开始编码的。所以我们需要先对 API 达成一致。
提示:
命名很重要!不要觉得把时间花在为变量起名字上很浪费。特别是当这些名称会长期使用的时候 - 记住,GraphQL API 并没有版本号这回事儿,所以,尽可能让你的 Schema 具有自解释特性,因为这是其他开发人员了解项目的入口。
下面是我为这个项目提供的 GraphQL Schema:
type Tweet {
id: ID!
# The tweet text. No more than 140 characters!
body: String
# When the tweet was published
date: Date
# Who published the tweet
Author: User
# Views, retweets, likes, etc
Stats: Stat
}
type User {
id: ID!
username: String
first_name: String
last_name: String
full_name: String
name: String @deprecated
avatar_url: Url
}
type Stat {
views: Int
likes: Int
retweets: Int
responses: Int
}
type Notification {
id: ID
date: Date
type: String
}
type Meta {
count: Int
}
scalar Url
scalar Date
type Query {
Tweet(id: ID!): Tweet
Tweets(limit: Int, sortField: String, sortOrder: String): [Tweet]
TweetsMeta: Meta
User: User
Notifications(limit: Int): [Notification]
NotificationsMeta: Meta
}
type Mutation {
createTweet(body: String): Tweet
deleteTweet(id: ID!): Tweet
markTweetRead(id: ID!): Boolean
}我在这个系列的前一篇文章中简短的介绍了 Schema 的语法。你只需要知道,这里的 type 类似 REST 里的 resources 概念。你可以用它来定义拥有唯一 id 键的实体(如 Tweet 和 User)。你也可以用它来定义值对象,这种类型嵌套在实体内部,因此不需要唯一键(例如 Stat)。
提示:
尽可能保证 Type 足够轻巧,然后利用组合。举个例子,尽管 stats 数据现在看来和 tweet 数据关系很近,但是请分开定义它们。因为它们表达的领域不同。这样当有天将 stats 数据换其它底层架构来维护,你就会庆幸今天做出的这个决定。
Query 和 Mutation 关键字有特别的含义,它们用来定义 API 的入口。所以,你不能声明一个自定义类型用这两个关键字,因为它们是 GraphQL 预留关键字。你可能会对 Query 下定义的字段有个困扰,它们总是和实体类型名字一样,但这只是个习惯约定。我就决定把获取 Tweet 类型数据的属性名称定义成 getTweet - 记住,GraphQL 是一种 RPC。
官方 GraphQL 提供的 schema 文档提供了所有细节,花十分钟来了解一下对你定义自己的 schema 会很有帮助。
提示:
你可能看过有些 GraphQL 教程使用代码风格来定义 schema,例如 GraphQLObjectType。别这么做,这种风格显得非常的啰嗦,也不够清晰。
创建一个简单的 GraphQL 服务端
用 Nodejs 实现一个 HTTP 服务端最快的方式是使用 express microframework。稍后我们会在 http://localhost:4000/graphql 下接入一个 GraphQL 服务。
> npm install express express-graphql graphql-tools graphql --saveexpress-graphql 库会基于我们定义的 schema 和 resolver 函数来创建一个 graphQL 服务。graphql-tools 库提供了 schema 的解析和校验的独立包。这两个库前者是来自于 Facebook,后者源于 Apollo。
// in src/index.js
const fs = require('fs');
const path = require('path');
const express = require('express');
const graphqlHTTP = require('express-graphql');
const { makeExecutableSchema } = require('graphql-tools');
const schemaFile = path.join(__dirname, 'schema.graphql');
const typeDefs = fs.readFileSync(schemaFile, 'utf8');
const schema = makeExecutableSchema({ typeDefs });
var app = express();
app.use('/graphql', graphqlHTTP({
schema: schema,
graphiql: true,
}));
app.listen(4000);
console.log('Running a GraphQL API server at localhost:4000/graphql');执行下面命令来让我们的服务端跑起来:
> node src/index.js
Running a GraphQL API server at localhost:4000/graphql我们可以使用 curl 来简单请求一下我们的 graphQL 服务:
> curl 'http://localhost:4000/graphql' \
> -X POST \
> -H "Content-Type: application/graphql" \
> -d "{ Tweet(id: 123) { id } }"
{
"data": {"Tweet":null}
}一切正常!
Graphql 服务根据我们提供的 schema 定义,在执行请求携带的查询语句之前进行了必要的校验,如果我们的查询语句中包含了一个没有声明过的字段,我们会得到一个错误提醒:
> curl 'http://localhost:4000/graphql' \
> -X POST \
> -H "Content-Type: application/graphql" \
> -d "{ Tweet(id: 123) { foo } }"
{
"errors": [
{
"message": "Cannot query field \"foo\" on type \"Tweet\".",
"locations": [{"line":1,"column":26}]
}
]
}提示:
express-graphql 包生成的 GraphQL 服务端同时支持 GET 和 POST 请求。提示:
另外还有一个不错的库可以让我们基于 express,koa,HAPI 或 Restify 来建立 GraphQL 服务:apollo-server。使用的方法和我们用的这个没有太多差异,所以这个教程同样适用。
GraphiQL:Graphql 领域的 Postman
curl 并不是一个很好用的工具来测试我们的 GraphQL 服务。我们使用 GraphiQL 来做可视化工具,你可以把它想象成是 Postman。
因为我们在使用 graphqlHTTP 中间件时声明了 graphiql 参数,GraphiQL 已经启动了。我们可以在浏览器访问 http://localhost:4000/graphql 就能看到 Web 界面了。它会从我们的服务中拿到完整的 schema 结构,并创建一个可视化的文档。可以点击页面右上角的 Docs 链接来查看:
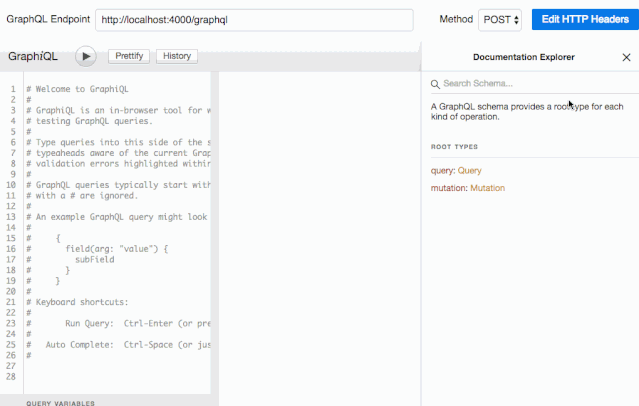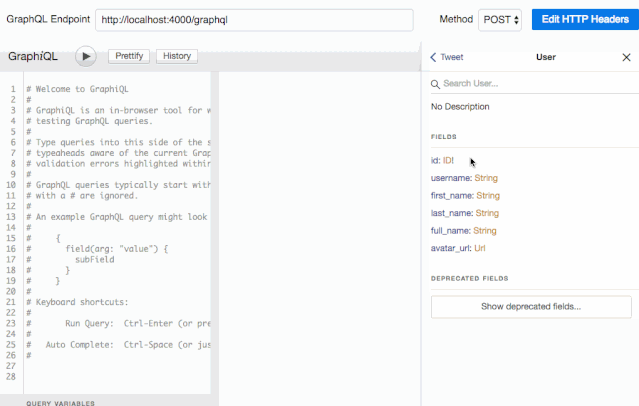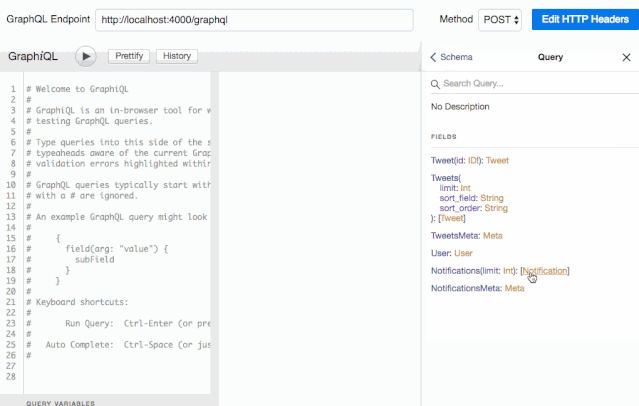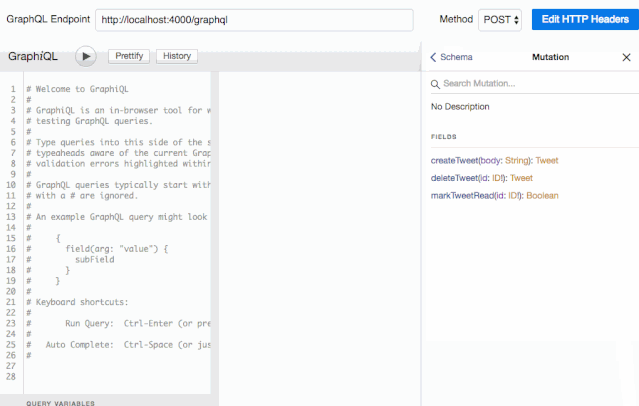
有了它,我们的服务端就相当于有了自动化 API 文档生成功能,这就意味着我们不再需要 Swagger 了。
提示:
文档中每个类型和字段的解释来自于 schema 中的注释(以 #为首的行)。尽可能提供注释,其它开发者会痛哭流涕的。
这还不是全部:使用 schema,GraphiQL 还提供了自动补全功能:
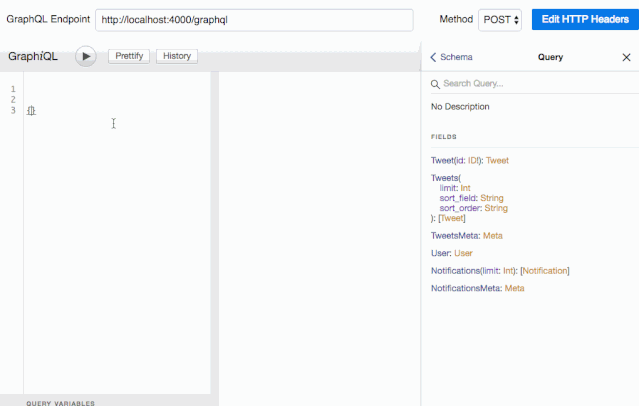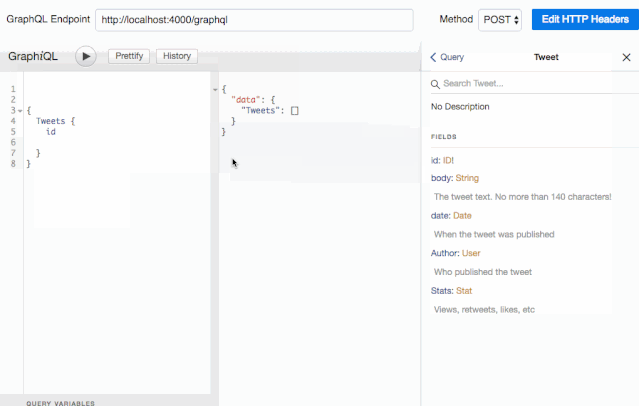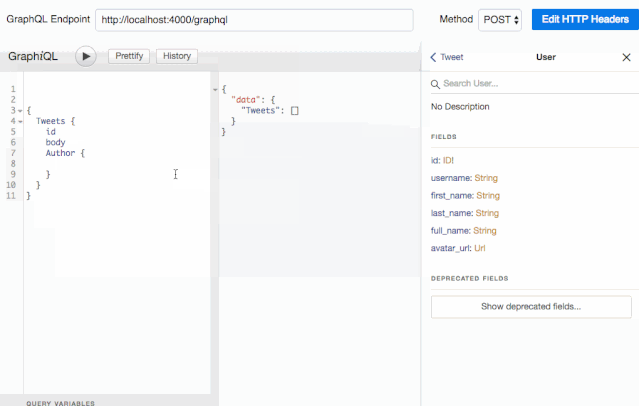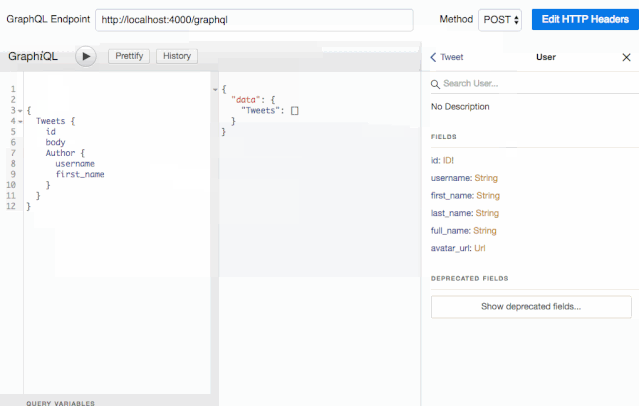
这种杀手级应用,每个 Graphql 开发者都值得拥有。对了,不要忘记在产品环境关闭它。
提示:
你可以独立安装 graphiQL 工具,它基于 Electron。跨平台的哦,下载链接
编写 Resolvers
到目前为止,我们的服务也只能返回空结果。我们这里会添加 resolver 定义来让它返回一些数据。我们先简单使用一些直接定义在代码里的静态数据来演示一下:
const tweets = [
{ id: 1, body: 'Lorem Ipsum', date: new Date(), author_id: 10 },
{ id: 2, body: 'Sic dolor amet', date: new Date(), author_id: 11 }
];
const authors = [
{ id: 10, username: 'johndoe', first_name: 'John', last_name: 'Doe', avatar_url: 'acme.com/avatars/10' },
{ id: 11, username: 'janedoe', first_name: 'Jane', last_name: 'Doe', avatar_url: 'acme.com/avatars/11' },
];
const stats = [
{ tweet_id: 1, views: 123, likes: 4, retweets: 1, responses: 0 },
{ tweet_id: 2, views: 567, likes: 45, retweets: 63, responses: 6 }
];然后我们来告诉服务如何使用这些数据来处理 Tweet 和 Tweets 查询请求。下面列出了 resolver 映射关系,这个对象按照 schema 的结构,为每个字段提供了一个函数:
const resolvers = {
Query: {
Tweets: () => tweets,
Tweet: (_, { id }) => tweets.find(tweet => tweet.id == id),
},
Tweet: {
id: tweet => tweet.id,
body: tweet => tweet.body
}
};
// pass the resolver map as second argument
const schema = makeExecutableSchema({ typeDefs, resolvers });
// proceed with the express app setup提示:
官方 express-graphql 文档建议使用 rootValue 选项来代替使用 makeExecutableSchema ()。我不推荐这么做!
这里 resolver 的函数签名是 (previousValue, parameters) => data。目前已经足够我们的服务来完成基础查询了:
// query { Tweets { id body } }
{
data:
Tweets: [
{ id: 1, body: 'Lorem Ipsum' },
{ id: 2, body: 'Sic dolor amet' }
]
}
// query { Tweet(id: 2) { id body } }
{
data:
Tweet: { id: 2, body: 'Sic dolor amet' }
}内部工作流程是这样的:服务会由外向内依次处理查询块,为每个查询块执行对应的 resolver 函数,并传递外层调用是的返回结果为第一个参数。所以,{Tweet (id: 2) { id body } } 这个查询的处理步骤为:
- 最外层为 Tweet,对应的 resolver 为 (Query.Tweet)。因为是最外层,所以调用 resolver 函数时第一个参数为
null。第二个参数传递的是查询携带的参数{ id: 2 }。根据 schema 的定义,该resolver函数会返回满足条件的 Tweet 类型对象。 - 针对每个 Tweet 对象,服务会执行对应的 (Tweet.id) 和 (Tweet.body)
resolver函数。此时第一个参数为第一步得到的 Tweet 对象。
目前我们的 Tweet.id 和 Tweet.bodyresolver 函数非常的简单,事实上我根本不需要声明它们。GraphQL 有一个简单的默认 resolver 来处理缺少对应定义的字段。
Mutation resolver 的实现并不会难多少,如下:
const resolvers = {
// ...
Mutation: {
createTweet: (_, { body }) => {
const nextTweetId = tweets.reduce((id, tweet) => {
return Math.max(id, tweet.id);
}, -1) + 1;
const newTweet = {
id: nextTweetId,
date: new Date(),
author_id: currentUserId, // <= you'll have to deal with that
body,
};
tweets.push(newTweet);
return newTweet;
}
},
};提示:
保持 resolver 函数的简洁。GraphQL 通常扮演系统的 API 网关角色,对后端领域服务提供了一层薄薄封装。resolver 应该只包含解析请求参数并生成返回数据要求的结构的功能 - 就好像 MVC 框架中的 controller 层。其它逻辑应该拆分到对应的层,这样我们就能保持 GraphQL 非侵入业务。
你可以在 Apollo 官网找到关于 resolvers 的完整文档。
处理数据依赖关系
接下来,最有意思的部分要开始了。如何让我们的服务能支持复杂的聚合查询呢?如下:
{
Tweets {
id
body
Author {
username
full_name
}
Stats {
views
}
}
}如果是在 SQL 语言,这可能需要对其它两个表的 joins 操作(User 和 Stat),其背后 SQL 执行器要运行复杂的逻辑来处理查询。在 GraphQL 中,我们只需要为 Tweet 类型添加合适的 resolver 函数即可:
const resolvers = {
Query: {
Tweets: () => tweets,
Tweet: (_, { id }) => tweets.find(tweet => tweet.id == id),
},
Tweet: {
Author: (tweet) => authors.find(author => author.id == tweet.author_id),
Stats: (tweet) => stats.find(stat => stat.tweet_id == tweet.id),
},
User: {
full_name: (author) => `${author.first_name} ${author.last_name}`
},
};
// pass the resolver map as second argument
const schema = makeExecutableSchema({ typeDefs, resolvers });有了上面的 resolvers,我们的服务就可以处理前面的查询并拿到期望的结果:
{
data: {
Tweets: [
{
id: 1,
body: "Lorem Ipsum",
Author: {
username: "johndoe",
full_name: "John Doe"
},
Stats: {
views: 123
}
},
{
id: 2,
body: "Sic dolor amet",
Author: {
username: "janedoe",
full_name: "Jane Doe"
},
Stats: {
views: 567
}
}
]
}
}看到这个结果我不知道大家什么反映,反正我第一次被震到了,这简直是黑科技。凭什么这么简单的 resolver 函数就能让服务支持这么复杂的查询?
我们再来看一下执行流程:
{
Tweets {
id
body
Author {
username
full_name
}
Stats {
views
}
}
}- 对于最外层的
Tweets查询块,GraphQL 执行Query.Tweetsresolver,第一个参数为null。resolver函数返回Tweets数组。 - 针对数组中的每个
Tweet,GraphQL 并发的执行Tweet.id、Tweet.body、Tweet.Author和Tweet.Statsresolver函数。 - 注意这次我并没有提供关于
Tweet.id和Tweet.body的resolver函数,GraphQL 使用默认的 resolver。对于Tweet.Authorresolver函数,会返回一个User类型的对象,这是 schema 中定义好的。 - 针对
User类型数据,查询会并发的执行User.username和User.full_nameresolver,并传递上一步得到的Author对象作为第一个参数。 State处理同样会使用默认的resolver来解决。
所以,这就是 GraphQL 的核心,非常的酷炫。它可以处理复杂的多层嵌套查询。这就是为啥成它为 Graph 的原因吧,此刻你应该顿悟了吧。
你可以在 graphql.org 网站找到关于 GraphQL 执行机制的描述。
对接真正的数据库
在真实项目中,resolver 需要和数据库或其它 API 打交道来获取数据。这和我们上面做的事儿没有本质不同,除了需要返回一个 Promise 外。假如 tweets 和 authors 数据存储在 PostgreSQL 数据库,而 Stats 存储在 MongoDB 数据库,我们的 resolver 只要调整一下即可:
const { Client } = require('pg');
const MongoClient = require('mongodb').MongoClient;
const resolvers = {
Query: {
Tweets: (_, __, context) => context.pgClient
.query('SELECT * from tweets')
.then(res => res.rows),
Tweet: (_, { id }, context) => context.pgClient
.query('SELECT * from tweets WHERE id = $1', [id])
.then(res => res.rows),
User: (_, { id }, context) => context.pgClient
.query('SELECT * from users WHERE id = $1', [id])
.then(res => res.rows),
},
Tweet: {
Author: (tweet, _, context) => context.pgClient
.query('SELECT * from users WHERE id = $1', [tweet.author_id])
.then(res => res.rows),
Stats: (tweet, _, context) => context.mongoClient
.collection('stats')
.find({ 'tweet_id': tweet.id })
.query('SELECT * from stats WHERE tweet_id = $1', [tweet.id])
.toArray(),
},
User: {
full_name: (author) => `${author.first_name} ${author.last_name}`
},
};
const schema = makeExecutableSchema({ typeDefs, resolvers });
const start = async () => {
// make database connections
const pgClient = new Client('postgresql://localhost:3211/foo');
await pgClient.connect();
const mongoClient = await MongoClient.connect('mongodb://localhost:27017/bar');
var app = express();
app.use('/graphql', graphqlHTTP({
schema: schema,
graphiql: true,
context: { pgClient, mongoClient }),
}));
app.listen(4000);
};
start();注意,由于我们的数据库操作只支持异步操作,所以我们需要改成 promise 写法。我把数据库链接句柄对象保存在 GraphQL 的 context 中,context 会作为第三个参数传递给所有的 resolver 函数。context 非常适合用来处理需要在多个 resolver 中共享的资源,有点类似其它框架中的注册表实例。
如你所见,我们很容易就做到从不同的数据源中聚合数据,客户端根本不知道数据来自于哪里:这一切都隐藏在 resolver 中。
1+N 查询问题
迭代查询语句块来调用对应的 resolver 函数确实聪明,但性能可能不太好。在我们的例子中,Tweet.Authorresolver 被调用了多次,针对每个从 Query.Tweetsresolve 中得到的 Tweet。所以我们请求了 1 次 Tweets,结果产生了 N 次 Tweet.Author 查询。
为了解决这个问题,我使用了另外一个库:Dataloader,它也是 Facebook 提供的。
npm install --save dataloaderDataLoader 是一个数据批量获取和缓存的工具库。首先我们会创建一个获取所有条目并返回 Promise 的函数,然后我们为每个条目创建一个 dataloader:
const DataLoader = require('dataloader');
const getUsersById = (ids) => pgClient
.query(`SELECT * from users WHERE id = ANY($1::int[])`, [ids])
.then(res => res.rows);
const dataloaders = () => ({
userById: new DataLoader(getUsersById),
});userById.load(id) 函数会收集多个单独的 item 调用,然后批量的获取一次。
提示:如果你不太熟悉 PostgreSQL,
WHERE id = ANY($1::int[])的语法就类似于WHERE id IN($1,$2,$3)。
我们把 dataloader 也保存在 context 中:
app.use('/graphql', graphqlHTTP(req => ({
schema: schema,
graphiql: true,
context: { pgClient, mongoClient, dataloaders: dataloaders() },
})));现在我们只需要稍微修改一下 Tweet.Authorresolver 即可:
const resolvers = {
// ...
Tweet: {
Author: (tweet, _, context) =>
context.dataloaders.userById.load(tweet.author_id),
},
// ...
};大功搞成!现在 { Tweets { Author { username } } 查询只会执行 2 次查询请求:
- 一次用来获取
Tweets数据 - 一次用来获取所有需要的
Tweet.Author数据
你需要注意一个细节:在 graphqlHTTP 配置时,我传递进去的是一个函数 (graphqlHTTP (req => ({ ... }))),而非之前的对象 (graphqlHTTP ({ ... }))。这是因为 Dataloader 实例还提供缓存功能,所以我需要确保所有请求使用的是同一个 Dataloader 对象。
但这次变动会导致前面的代码报错,因为 pgClient 在 getUsersById 函数的上下文中就不存在了。为了传递数据库链接句柄到 dataloader 中,这有点绕,看下面的代码:
const DataLoader = require('dataloader');
const getUsersById = pgClient => ids => pgClient
.query(`SELECT * from users WHERE id = ANY($1::int[])`, [ids])
.then(res => res.rows);
const dataloaders = pgClient => ({
userById: new DataLoader(getUsersById(pgClient)),
});
// ...
app.use('/graphql', graphqlHTTP(req => ({
schema: schema,
graphiql: true,
context: { pgClient, mongoClient, dataloaders: dataloaders(pgClient) },
})));实际开发中,你可能不得不在所有的 resolver 函数中都使用 dataloader,不管是否会查询数据库。这是产品环境下的必备啊,千万别错过它!
管理自定义 Scalar 类型
你可能注意到了我到现在为止都没有获取 tweet.date 数据,那是因为我在 schema 中定义了自定义的 scalar 类型:
type Tweet {
# ...
date: Date
}
scalar Date不管你信不信,反正 graphQL 规范中并没有定义 Date scalar 类型,需要开发者自行实现。这算是个好的机会我们来演示一下创建自定义 scalar 类型,用来校验和类型转换数据。
和其他类型一样,scalar 类型也需要 resolver。但它的 resolver 函数必须支持将数据从其它 resolver 函数中转换为响应所需的格式,反之亦然:
const { GraphQLScalarType, GraphQLError } = require('graphql');
const { Kind } = require('graphql/language');
const validateValue = value => {
if (isNaN(Date.parse(value))) {
throw new GraphQLError(`Query error: not a valid date`, [value]);
};
const resolvers = {
// previous resolvers
// ...
Date: new GraphQLScalarType({
name: 'Date',
description: 'Date type',
parseValue(value) {
// value comes from the client, in variables
validateValue(value);
return new Date(value); // sent to resolvers
},
parseLiteral(ast) {
// value comes from the client, inlined in the query
if (ast.kind !== Kind.STRING) {
throw new GraphQLError(`Query error: Can only parse dates strings, got a: ${ast.kind}`, [ast]);
}
validateValue(ast.value);
return new Date(ast.value); // sent to resolvers
},
serialize(value) {
// value comes from resolvers
return value.toISOString(); // sent to the client
},
}),
};错误处理
正是因为咱们有 schema,所有错误的查询请求都会被服务端捕获,并返回一个错误提醒:
// query { Tweets { id body foo } }
{
"errors": [
{
"message": "Cannot query field \"foo\" on type \"Tweets\".",
"locations": [
{
"line": 1,
"column": 19
}
]
}
]
}这让调试变得易如反掌。客户端用户可以看到到底发生了什么事儿。
但这种在响应中显示错误信息的简单处理,并没有在服务端记录错误日志。为了帮助开发者跟踪异常,我在 makeExecutableSchema 中配置了 logger 参数,它必须传递一个拥有 log 方法的对象:
const schema = makeExecutableSchema({
typeDefs,
resolvers,
logger: { log: e => console.log(e) },
});如果你打算在响应中隐藏错误信息,可以使用 graphql-errors 包。
日志
除了数据和错误外,graphQL 的响应中还可以包含 extensions 类信息,你可以在其中放你想要的任何数据。我们用它来显示服务的耗时信息再好不过了。
为了添加扩展信息,我们需要在 graphqlHTTP 配置中添加 extension 函数,它返回一个支持 json 序列化的对象。
下面我添加了一个 timing 到响应中:
app.use('/graphql', graphqlHTTP(req => {
const startTime = Date.now();
return {
// ...
extensions: ({ document, variables, operationName, result }) => ({
timing: Date.now() - startTime,
})
};
})));现在我们所有的 graphQL 响应中都会包含请求的耗时信息:
// query { Tweets { id body } }
{
"data": [ ... ],
"extensions": {
"timing": 53,
}
}你可以按你的设想为你的 resolver 函数提供更细颗粒度的耗时信息。在产品环境下,监听每个后端响应耗时非常有意义。你可以参考 apollo-tracing-js:
{
"data": <>,
"errors": <>,
"extensions": {
"tracing": {
"version": 1,
"startTime": <>,
"endTime": <>,
"duration": <>,
"execution": {
"resolvers": [
{
"path": [<>, ...],
"parentType": <>,
"fieldName": <>,
"returnType": <>,
"startOffset": <>,
"duration": <>,
},
...
]
}
}
}
}Apollo公司还提供一个叫 Optics 的 GraphQL 监控服务,不妨试试看。
认证 & 中间件
GraphQL 规范中并没有包含认证授权相关的内容。这意味着你不得不自己来做,可以使用 express 对应的中间件库(你可能需要 passport.js)。
一些教程推荐使用 graphQL 的 Mutation 来实现注册和登录功能,并且在 resolver 函数中实现认证逻辑。但我的观点是,这在多数场景中都显得过火了。
请记住,GraphQL 只是一个 API 网关,它不应该处理太多的业务需求。
Resolvers 的单元测试
resolver 是简单函数,所以单元测试非常简单。在这篇教程里,我们会使用同样是 Facebook 提供的 Jest,因为它基本上开箱即用:
> npm install jest --save-dev让我们开始为之前写的 resolver 函数 User.full_name 来写个测试用例。为了能测试它,我们需要先把它单独拆分到自己的文件中:
// in src/user/resolvers.js
exports.User = {
full_name: (author) => `${author.first_name} ${author.last_name}`,
};
// in src/index.js
const User = require('./resolvers/User');
const resolvers = {
// ...
User,
};
const schema = makeExecutableSchema({ typeDefs, resolvers });
// ...现在就可以对它写测试用例了:
// in src/user/resolvers.spec.js
const { User } = require('./resolvers');
describe('User.full_name', () => {
it('concatenates first and last name', () => {
const user = { first_name: 'John', last_name: 'Doe' };
expect(User.full_name(user)).toEqual('John Doe')
});
})运行 ./node_modules/.bin/jest,然后就可以看到终端显示的测试结果了。
那些和数据库打交道的 resolver 测试起来可能稍微麻烦一些。不过因为 context 会被当做参数,我们利用它来传入测试数据集也没什么难的。如下:
// in src/tweet/resolvers.js
exports.Query = {
Tweets: (_, _, context) => context.pgClient
.query('SELECT * from tweets')
.then(res => res.rows),
};
// in src/tweet/resolvers.spec.js
const { Query } = require('./resolvers');
describe('Query.Tweets', () => {
it('returns all tweets', () => {
const queryStub = q => {
if (q == 'SELECT * from tweets') {
return Promise.resolve({ rows: [
{ id: 1, body: 'hello' },
{ id: 2, body: 'world' },
]});
}
};
const context = { pgClient: { query: queryStub } };
return Query.Tweets(null, null, context).then(results => {
expect(results).toEqual([
{ id: 1, body: 'hello' }
{ id: 2, body: 'world' }
]);
});
});
})注意这里依然需要返回一个 Promise,并且将断言语句放在 then() 回调中。这样 Jest 会知道是异步测试。我们刚才是手动编写测试数据的,在真实产品中,你可能需要一个专业的类库来帮忙:Sinon.js。
如你所见,测试 resolver 就是这么小菜一碟。把 resolver 定位为一个纯函数,是 GraphQL 设计者们的另一个明智之举。
查询引擎的集成化测试
那么,如何来测试数据依赖,类型和聚合逻辑呢?这是另一种类型的测试,一般叫集成测试,需要在查询引擎上跑。
这需要我们运行一个 HTTP Server 来进行继承测试么?然而并不是。你可以单独对查询引擎进行测试而不需要跑一个服务,使用 GraphQL 工具即可。
在集成测试之前,我们需要调整一下代码结构:
// in src/schema.js
const fs = require('fs');
const path = require('path');
const { makeExecutableSchema } = require('graphql-tools');
const resolvers = require('../resolvers'); // extracted from the express app
const schemaFile = path.join(__dirname, './schema.graphql');
const typeDefs = fs.readFileSync(schemaFile, 'utf8');
module.exports = makeExecutableSchema({ typeDefs, resolvers });
// in src/index.js
const express = require('express');
const graphqlHTTP = require('express-graphql');
const schema = require('./schema');
var app = express();
app.use('/graphql', graphqlHTTP({
schema,
graphiql: true,
}));
app.listen(4000);
console.log('Running a GraphQL API server at localhost:4000/graphql');现在我就可以单独的测试 schema:
// in src/schema.spec.js
const { graphql } = require('graphql');
const schema = require('./schema');
it('responds to the Tweets query', () => {
// stubs
const queryStub = q => {
if (q == 'SELECT * from tweets') {
return Promise.resolve({ rows: [
{ id: 1, body: 'Lorem Ipsum', date: new Date(), author_id: 10 },
{ id: 2, body: 'Sic dolor amet', date: new Date(), author_id: 11 }
]});
}
};
const dataloaders = {
userById: {
load: id => {
if (id == 10 ) {
return Promise.resolve({ id: 10, username: 'johndoe', first_name: 'John', last_name: 'Doe', avatar_url: 'acme.com/avatars/10' });
}
if (id == 11 ) {
return Promise.resolve({
{ id: 11, username: 'janedoe', first_name: 'Jane', last_name: 'Doe', avatar_url: 'acme.com/avatars/11' });
}
}
}
};
const context = { pgClient: { query: queryStub }, dataloaders };
// now onto the test itself
const query = '{ Tweets { id body Author { username } }}';
return graphql(schema, query, null, context).then(results => {
expect(results).toEqual({
data: {
Tweets: [
{ id: '1', body: 'hello', Author: { username: 'johndoe' } },
{ id: '2', body: 'world', Author: { username: 'janedoe' } },
],
},
});
});
})这个独立的 graphql 查询引擎的 api 方法签名是 (schema, query, rootValue, context) => Promise。很简单对吧?顺便说一句,graphql HTTP 内部就是调用它来工作的。
另一种 Apollo 公司比较推荐的测试手段是使用来自 graphql-tools 中的 mockServer 来测试。基于文本化的 schema,它会创建一个内存数据源,并填充伪造的数据。你可以在这个教程中看到详细步骤。然而我并不推荐这种方式 - 它更像是一个前端开发者的工具,用来模拟 GraphQL 服务,而不是用来测试 resolver。
Resolvers 拆分
为了能测试 resolver 和查询引擎,我们不得不把代码拆分到多个独立的文件中。从开发者角度来看这是一个值得的工作 - 它提供了模块化和可维护性。让我们完成所有 resolver 的模块化拆分。
// in src/tweet/resolvers.js
export const Query = {
Tweets: (_, _, context) => context.pgClient
.query('SELECT * from tweets')
.then(res => res.rows),
Tweet: (_, { id }, context) => context.pgClient
.query('SELECT * from tweets WHERE id = $1', [id])
.then(res => res.rows),
}
export const Mutation = {
createTweet: (_, { body }, context) => context.pgClient
.query('INSERT INTO tweets (date, author_id, body) VALUES ($1, $2, $3) RETURNING *', [new Date(), currentUserId, body])
.then(res => res.rows[0])
},
}
export const Tweet = {
Author: (tweet, _, context) => context.dataloaders.userById.load(tweet.author_id),
Stats: (tweet, _, context) => context.dataloaders.statForTweet.load(tweet.id),
},
// in src/user/resolvers.js
export const Query = {
User: (_, { id }, context) => context.pgClient
.query('SELECT * from users WHERE id = $1', [id])
.then(res => res.rows),
};
export const User = {
full_name: (author) => `${author.first_name} ${author.last_name}`,
};然后我们需要在一个地方合并所有的 resolver:
// in src/resolvers
const {
Query: TweetQuery,
Mutation: TweetMutation,
Tweet,
} = require('./tweet/resolvers');
const { Query: UserQuery, User } = require('./user/resolvers');
module.exports = {
Query: Object.assign({}, TweetQuery, UserQuery),
Mutation: Object.assign({}, TweetMutation),
Tweet,
User,
}就是这样!现在,模块化拆分后的代码结构,更适合理解和测试。
组织 Schemas
Resolvers 现在已经结构化了,但是 schema 呢?把所有定义都放在一个文件中一听就不是个好设计。尤其是对一些大项目,这会导致根本无法维护。就像 resolver 那样,我也会把 schema 拆分到多个独立的文件中。下面是我推荐的项目文件结构,靠模块思想来搭建:
src/
stat/
resolvers.js
schema.js
tweet/
resolvers.js
schema.js
user/
resolvers.js
schema.js
base.js
resolvers.js
schema.jsbase.js 文件中包含了 schema 的基础类型,和空的 query 和 mutation 类型声明,其它片段 schema 文件会增加对应的字段到其中。
// in src/base.js
const Base = `
type Query {
dummy: Boolean
}
type Mutation {
dummy: Boolean
}
type Meta {
count: Int
}
scalar Url
scalar Date`;
module.exports = () => [Base];由于 GraphQL 不支持空的类型,所以我们不得不声明一个看起来毫无意义的 query 和 mutation。注意,文件最后导出的是一个数组而非字符串。后面你就会知道是为啥了。
现在,在 User schema 声明文件中,我们如何添加字段到已经存在的 query 类型中?使用 graphql 关键字 extend:
// in src/user/schema.js
const Base = require('../base');
const User = `
extend type Query {
User: User
}
type User {
id: ID!
username: String
first_name: String
last_name: String
full_name: String
name: String @deprecated
avatar_url: Url
}
`;
module.exports = () => [User, Base];正如你看到的,代码最后并没有只是导出 User,也导出了 Base。我就是靠这种方法来确保 makeExecutableSchema 能拿到所有的类型定义。这就是为啥总是导出数组的原因。
Stat 类型也没有什么特殊的:
// in src/stat/schema.js
const Stat = `
type Stat {
views: Int
likes: Int
retweets: Int
responses: Int
}
`;
module.exports = () => [Stat];Tweet 类型依赖多个其它类型,所以我们要导入所有依赖的类型定义,并最终全部导出:
// in src/tweet/schema.js
const User = require('../user/schema');
const Stat = require('../stat/schema');
const Base = require('../base');
const Tweet = `
extend type Query {
Tweet(id: ID!): Tweet
Tweets(limit: Int, sortField: String, sortOrder: String): [Tweet]
TweetsMeta: Meta
}
extend type Mutation {
createTweet (body: String): Tweet
deleteTweet(id: ID!): Tweet
markTweetRead(id: ID!): Boolean
}
type Tweet {
id: ID!
# The tweet text. No more than 140 characters!
body: String
# When the tweet was published
date: Date
# Who published the tweet
Author: User
# Views, retweets, likes, etc
Stats: Stat
}
`;
module.exports = () => [Tweet, User, Stat, Base];最后,确保所有类型都在主 schema.js 文件中,我简单的传递一个 typeDefs 数组:
// in schema.js
const Base = require('./base.graphql');
const Tweet = require('./tweet/schema');
const User = require('../user/schema');
const Stat = require('../stat/schema');
const resolvers = require('./resolvers');
module.exports = makeExecutableSchema({
typeDefs: [
...Base,
...Tweet,
...User,
...Stat,
],
resolvers,
});不需要担心类型重叠问题。每个类型 makeExecutableSchema 只会接受一次。
提示:
子 schema 导出一个函数而不是一个数组,是因为它要确保不会发生环形依赖问题。makeExecutableSchema函数支持传递数组和函数参数。
结语
我们的服务端现在已经搞出来了,并且也进行了测试。你可以从 Github 上下载这个教程的完整代码。欢迎使用它来作为你新项目的脚手架。
其实还有一些我没有提到的关于服务端 GraphQL 开发的细节:
- 安全:客户端可以随意的创建复杂查询,这就增加了服务风险,例如被 DoS 攻击。可以看一下这篇文章: HowToGraphQL: GraphQL Security
- 订阅:很多教程使用 WebSocket,可以阅读 HowToGraphQL: Subscriptions 或 Apollo: Server-Side Subscriptions 来了解更多细节
- 输入类型:对于 mutations,GraphQL 支持有限的输入类型。可以从 Apollo: GraphQL Input Types And Client Caching 了解更多细节
- Persisted Queries:这个主题会在后续的文章中涉及。
注意:这篇教程中提到的大多数 js 库都源自 Facebook 或 Apollo。那么,Apollo 到底是哪位?它是来自于 Meteor 团队的一个项目。这些家伙为 GraphQL 贡献了很多的高质量代码。顶他们!但他们同时也靠售卖 GraphQL 相关服务来盈利,所以在盲目遵从他们提供的教程之前,你最好能有个备选方案。
开发一个 GraphQL 服务端需要比 REST 服务端更多的工作,但同样你也会得到加倍的回报。如果你在读这篇教程的时候被太多名词给吓到,先别着急,你回忆一下当初你学 RESTful 的时候(URIs,HTTP return code,JSON Schema,HATEOAS),但现在你已经是一个 REST 开发者了。我觉得多花一两天你也就掌握 GraphQL 了。这是非常值得投资的。
这个技术依然很年轻,并没有什么权威的最佳时间。我这里分享的只是我个人的积累。在我学习的过程中我看过大量的过时的教程,因为这门技术在不停的发展和进化。
感谢阅读,希望这篇教程不会那么快就过时!
扩展阅读:
