工具简介
Robots.txt 测试工具,是一款在线验证 robots.txt 规则的工具。通过 Robots.txt 测试工具,可以检测在 robots.txt 设定的规则下,网站指定的页面是否允许网络爬虫访问。
本工具支持的搜索引擎爬虫有:
- 百度爬虫 - BaiduSpider
- Google 爬虫 - GoogleBot
- Bing 爬虫 - BingBot
- 360 爬虫 - 360Spider
- 搜狗爬虫 - SougouSpider
- 宜搜爬虫 - YisouSpider
使用方法
首先,输入页面 URL,然后选择要检测的爬虫名称(当然,也可以选择 All(*),表示任意爬虫),点击【开始检测】按钮,即可得到检测结果。
以 https://www.dute.org/blog 页面为例,检测结果如下:
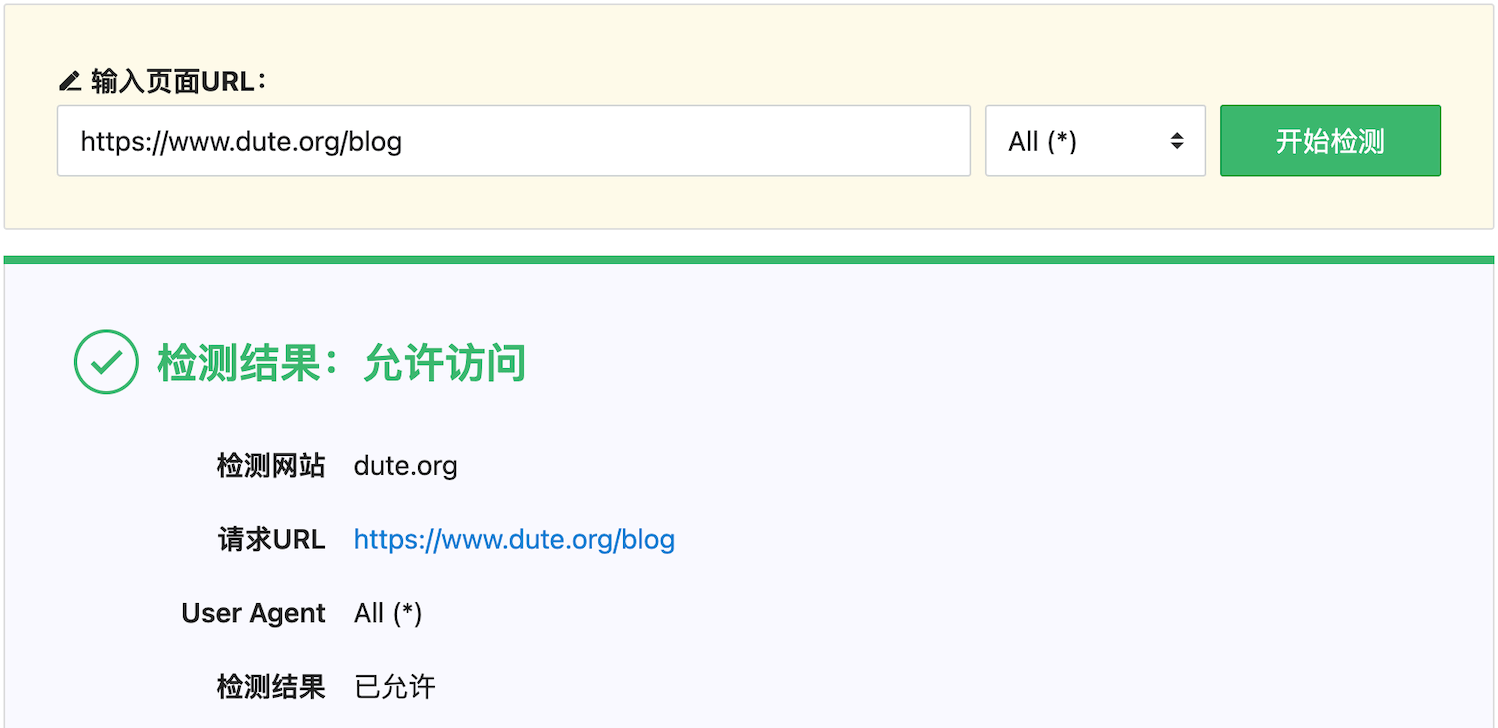
上述结果表示:对于所有爬虫,均可访问 https://www.dute.org/blog 页面。
再以微信公众号文章页面 https://mp.weixin.qq.com/s 为例,选择 BaiduSpider 进行检测,检测结果如下:
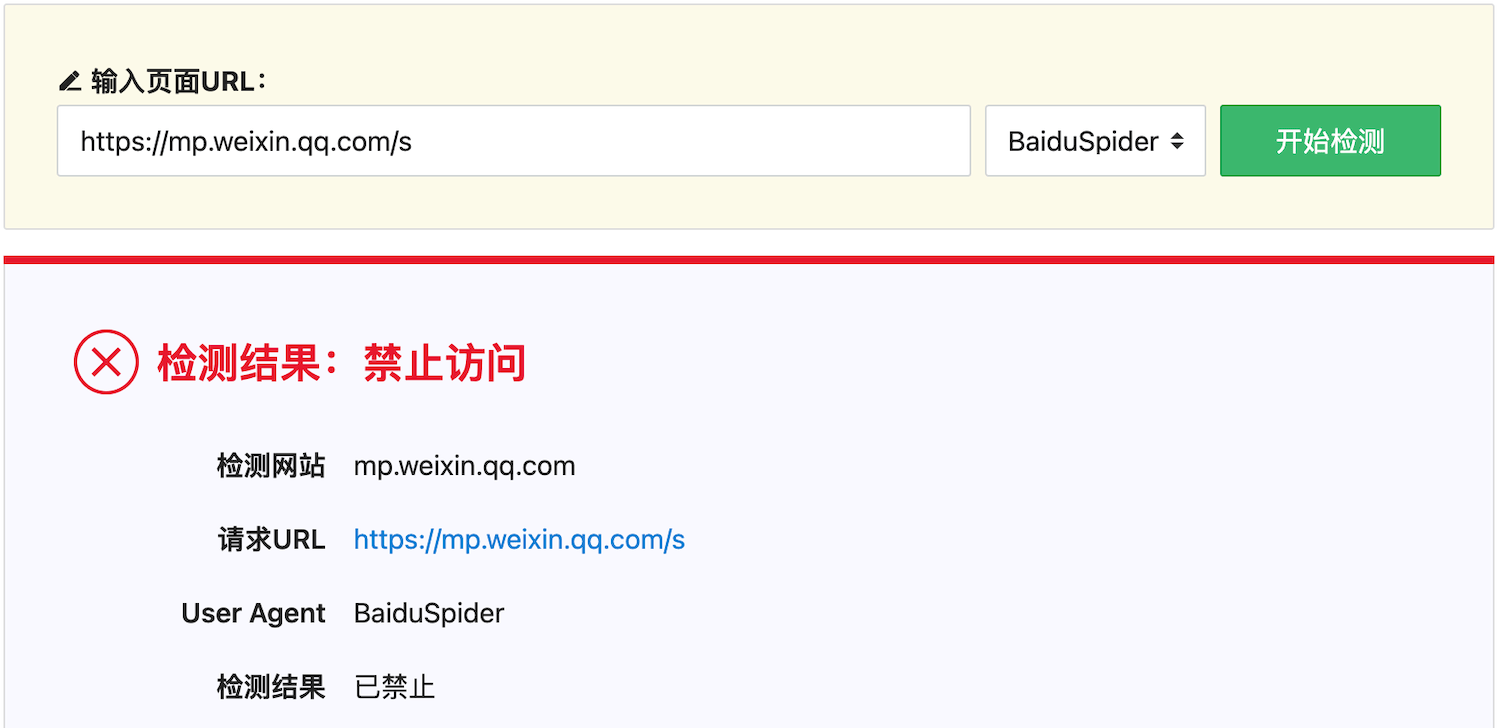
很明显,https://mp.weixin.qq.com/s 页面不允许百度爬虫访问。
其实,选择
All(*)也是同样的结果,说明微信公众号文章不允许爬虫爬取其内容。
如果检测到了网站的 robots.txt 文件,本工具还会显示 robots.txt 文件的内容。下面是本站 dute.org 的 robots.txt 的内容:

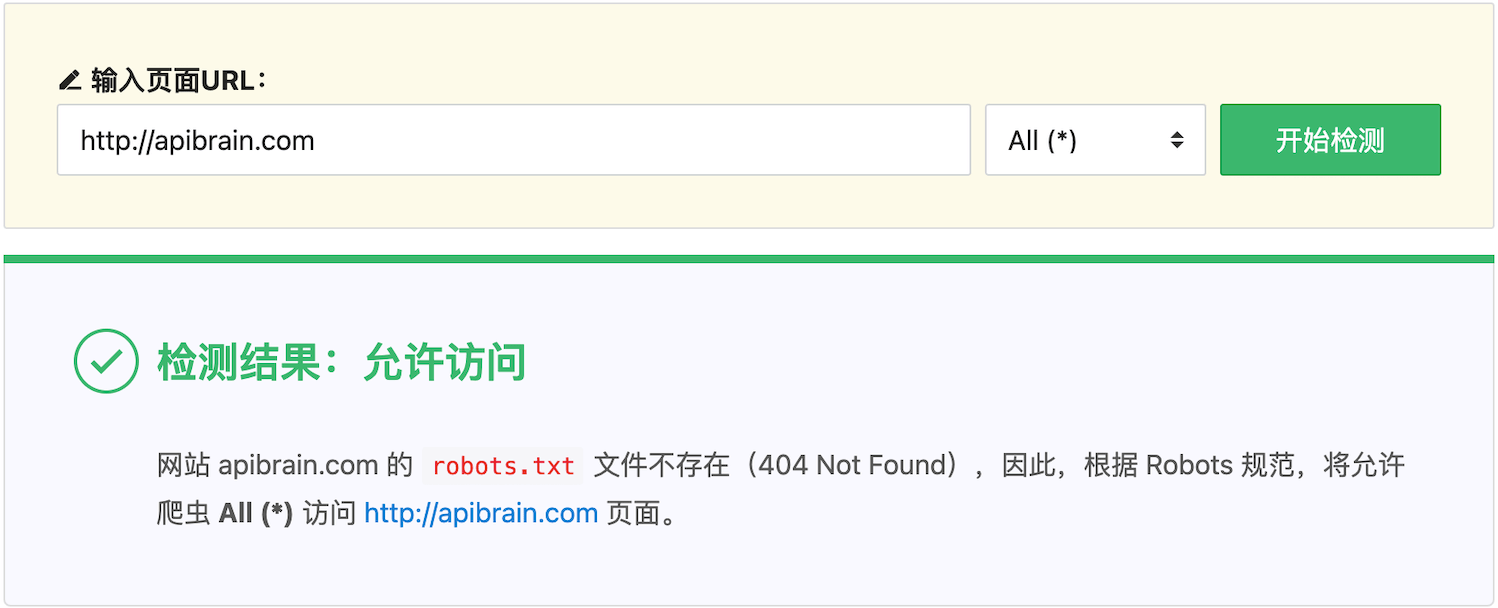
如果未检测到 robots.txt 文件,则会提示 robots.txt 文件不存在(robots.txt 文件对应的 URL 返回 404 状态码会认为文件不存在)。这种情况,被视为允许访问。道理很明显:作为互联网上可以公开访问的资源,如果网站未通过 robots.txt 的规则明确拒绝,则认为是允许访问的。
如下图所示:
还有一种情况是,robots.txt 的响应结果既不是 200,也不是 404,是一种未知状态。这种情况下,本工具会给出“检测结果未知”的提示:

robots.txt 简介
robots.txt 是一种存放于网站根目录下的 ASCII 编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络爬虫),此网站中的哪些内容是不应被搜索引擎的爬虫获取的,哪些是可以被爬虫获取的。因为一些系统中的URL是大小写敏感的,所以,robots.txt 的文件名应统一为小写。robots.txt 应放置于网站的根目录下。如果想单独定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的 robots.txt,或者使用 robots 元数据(Metadata,又称元数据)。
robots.txt 协议并不是一个规范,而只是一种约定俗成的用法(建议),是否遵守 robots.txt 规则,全凭搜索引擎自身的考虑,所以,并不能严格保证网站的隐私。
robots.txt 还允许使用类似 Disallow: *.gif 这样的通配符来匹配一组路径。
注意:robots.txt 是用字符串比较来确定是否获取 URL,因此,目录末尾有斜杠
/与没有斜杠,是 2 种不同的 URL。
除了 robots.txt 制定的规则外,其它影响搜索引擎爬虫行为的还有 robots 元数据:
<meta name="robots" content="noindex,nofollow" />上述 meta 标签,表示禁止搜索引擎索引和跟踪当前页。
提示:如果对 meta 标签不熟悉,本站提供了网页 meta 标签生成工具,可以方便地生成网页常用的 meta 标签,其中包括 robots meta 标签。
用法示例
下面展示了一些典型的 robots.txt 的规则示例。
1、允许所有爬虫访问
User-agent: *
Allow: /2、仅允许 GoogleBot 访问
User-agent: googlebot
Allow: /3、除了 /blog 外,禁止访问其它页面
User-agent: *
Allow: /blog
Disallow: /4、禁止访问(抓取) /cgi-bin/ 下面的文件
User-agent: *
Disallow: /cgi-bin/5、禁止访问根目录下的 .php 文件
User-agent: *
Disallow: /*.php$